WaveSP-Net: Learnable Wavelet-Domain Sparse Prompt Tuning
for Speech Deepfake Detection
for Speech Deepfake Detection
1 University of Eastern Finland 2 National Institute of Informatics
3 University of Chinese Academy of Sciences 4 National Taiwan University
5 University of Toronto 6 Tsinghua University
3 University of Chinese Academy of Sciences 4 National Taiwan University
5 University of Toronto 6 Tsinghua University
DEMO
Real vs Fake Audio Samples
Real Speech Sample
REAL
🔹 Real0001.wav – Detection Result: Real
(WaveSP-Net inference fake probability: 0.0323)
(WaveSP-Net inference fake probability: 0.0323)
Human voice, genuine recording.
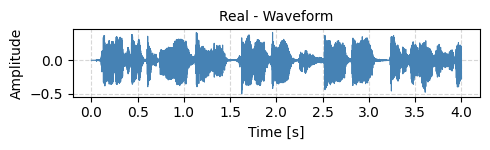
Figure R1. Waveform (Real)
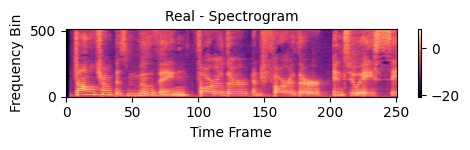
Figure R2. Spectrogram (Real)
Fake Speech Sample
FAKE
🔸 Fake0001.wav – Detection Result: Fake
(WaveSP-Net inference fake probability: 0.8272)
(WaveSP-Net inference fake probability: 0.8272)
AI-generated / synthesized voice.
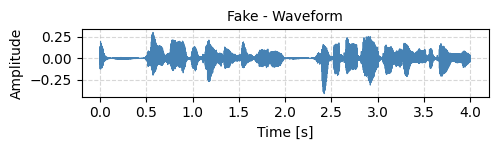
Figure F1. Waveform (Fake)
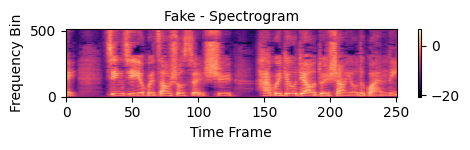
Figure F2. Spectrogram (Fake)
CITATION
Reference
@misc{xuan2025wavespnet,
title={WaveSP-Net: Learnable Wavelet-Domain Sparse Prompt Tuning for Speech Deepfake Detection},
author={Xi Xuan and Xuechen Liu and Wenxin Zhang and Yi-Cheng Lin and Xiaojian Lin and Tomi Kinnunen},
year={2025},
eprint={2510.05305},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2510.05305},
}